Purpose
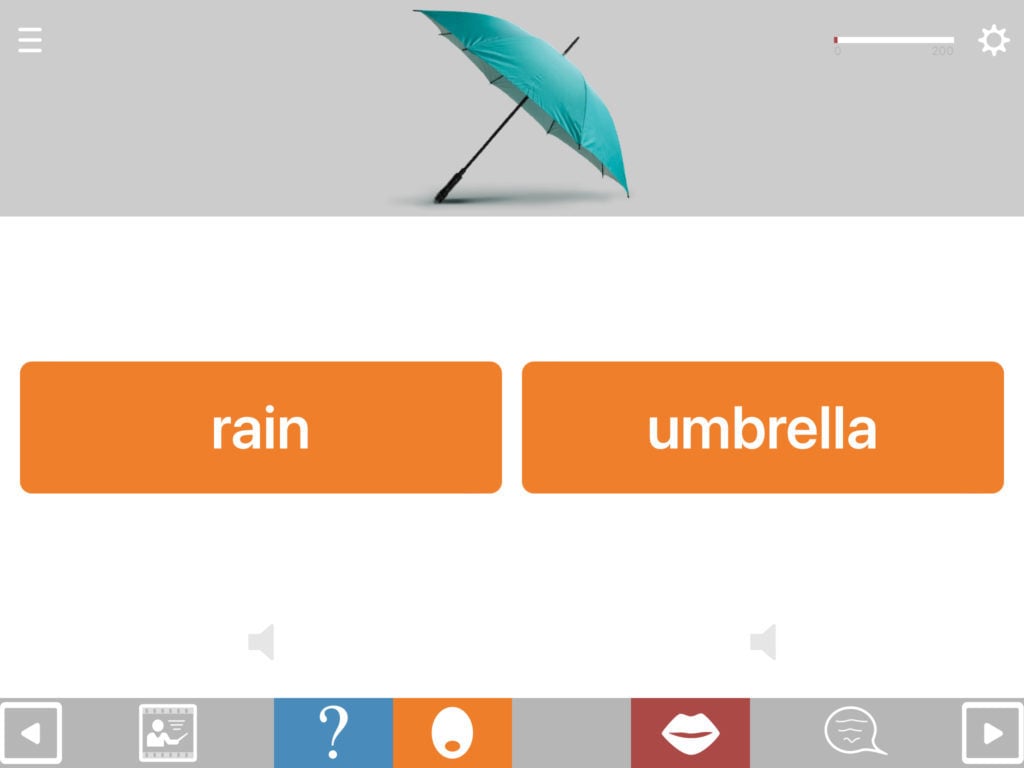
Matching is a long-established therapy technique that has been shown to result in improvements in both understanding and retrieving words. The most common types of matching tasks involve matching spoken or written words to pictures in the presence of distractors or foils.
Research has generally found that improvements in the exercise are item-specific. This means that improvements are restricted to the words worked on, i.e. the effects do not generalise to other words (e.g. Herbert 2014).
Cuespeak takes the traditional matching task and adds several extra features:
- A wider range of options for matching stimuli, including first letter, sound effects and videos of words being spoken
- Spoken feedback on errors
- Advanced options in selection of distractors, not just in number but also in type, including associate distractors to feed into work on contextual competition in word-finding
- Hand-picked distractors, to avoid the ambiguities often found among auto-generated distractors
- Picture-word matching is available in both directions, i.e. word to picture and picture to word
- Option to add up to two customised help buttons per question, choosing from 12 options
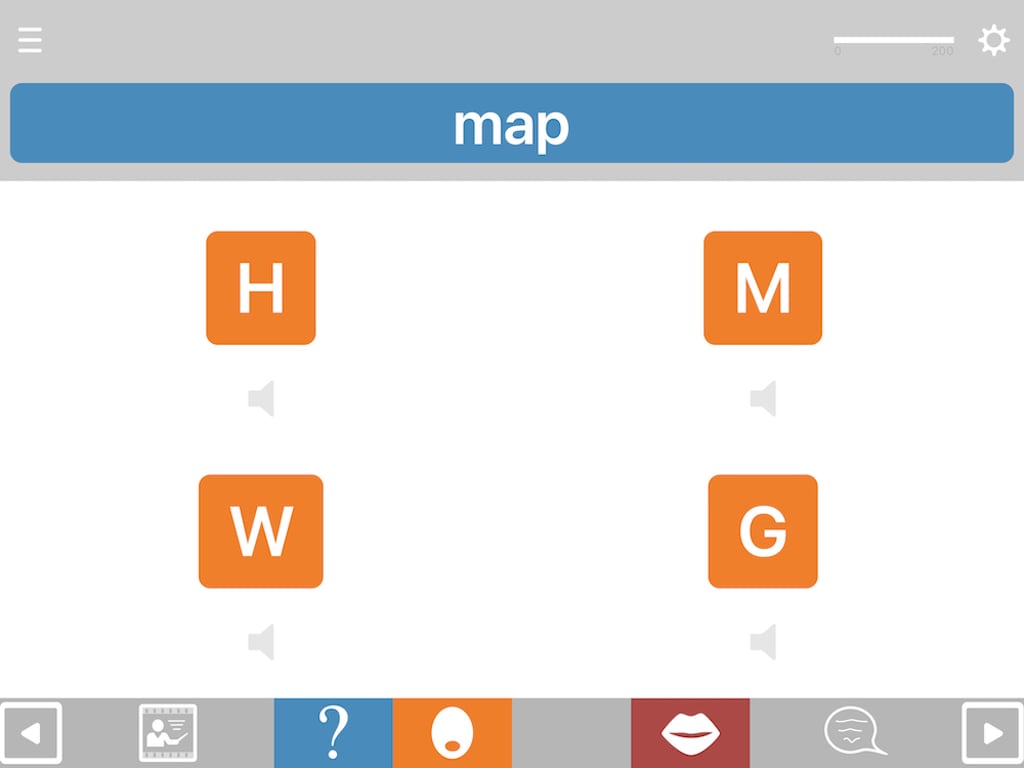
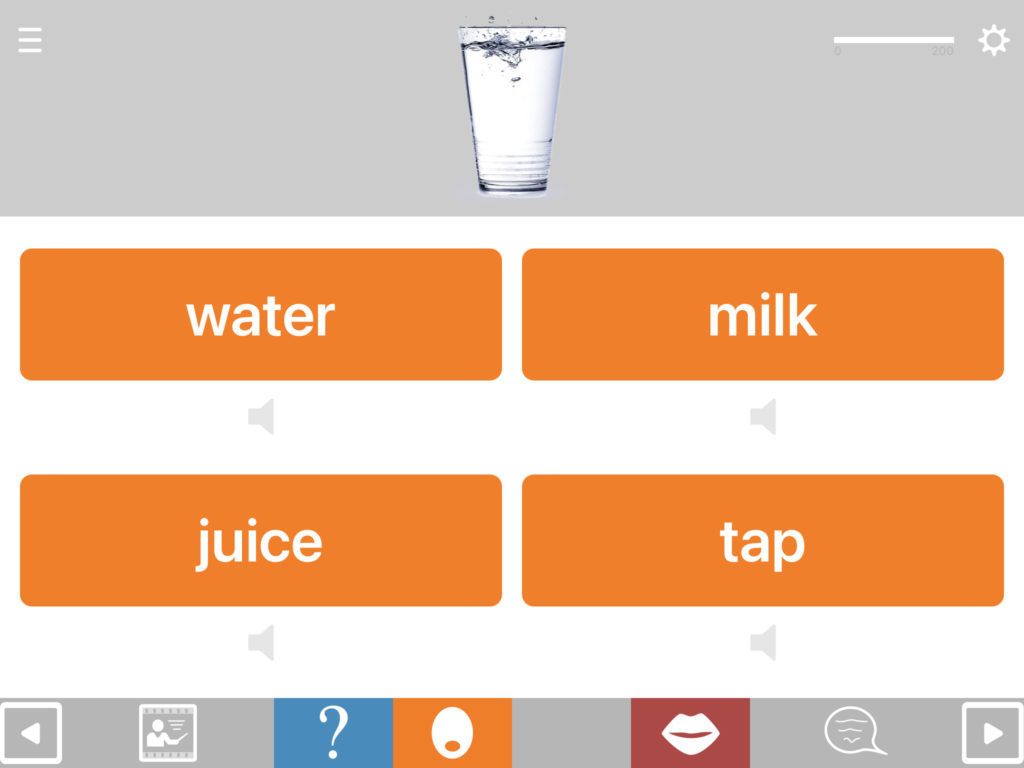
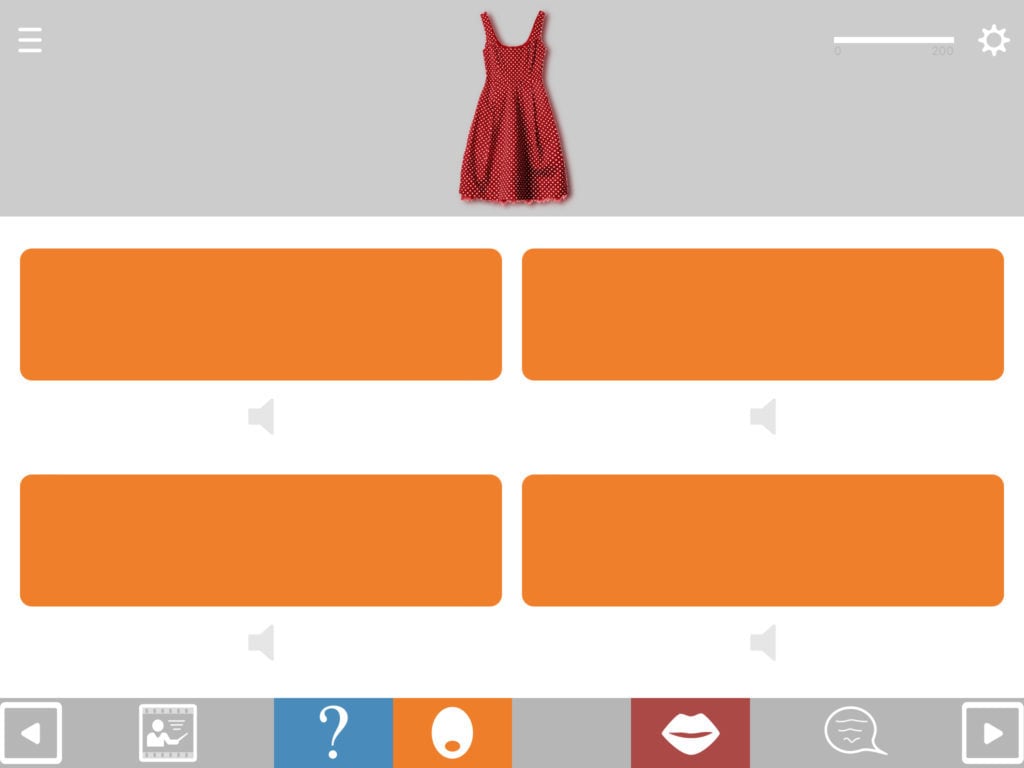
Match anything to anything
The available combination formats include matching:

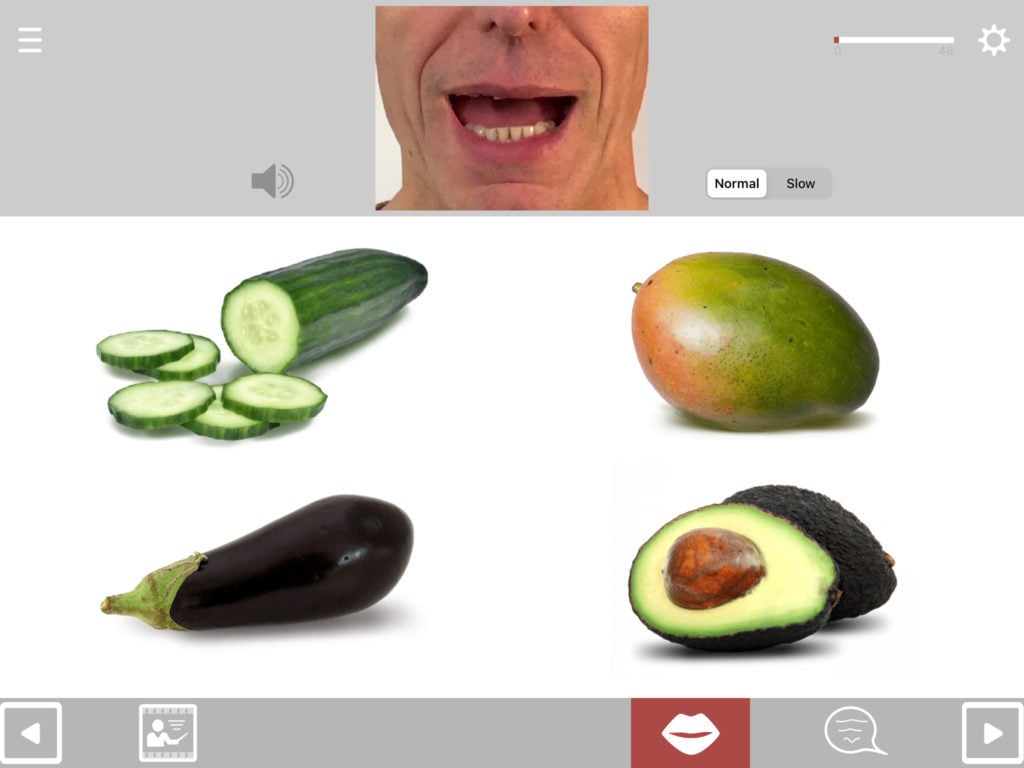
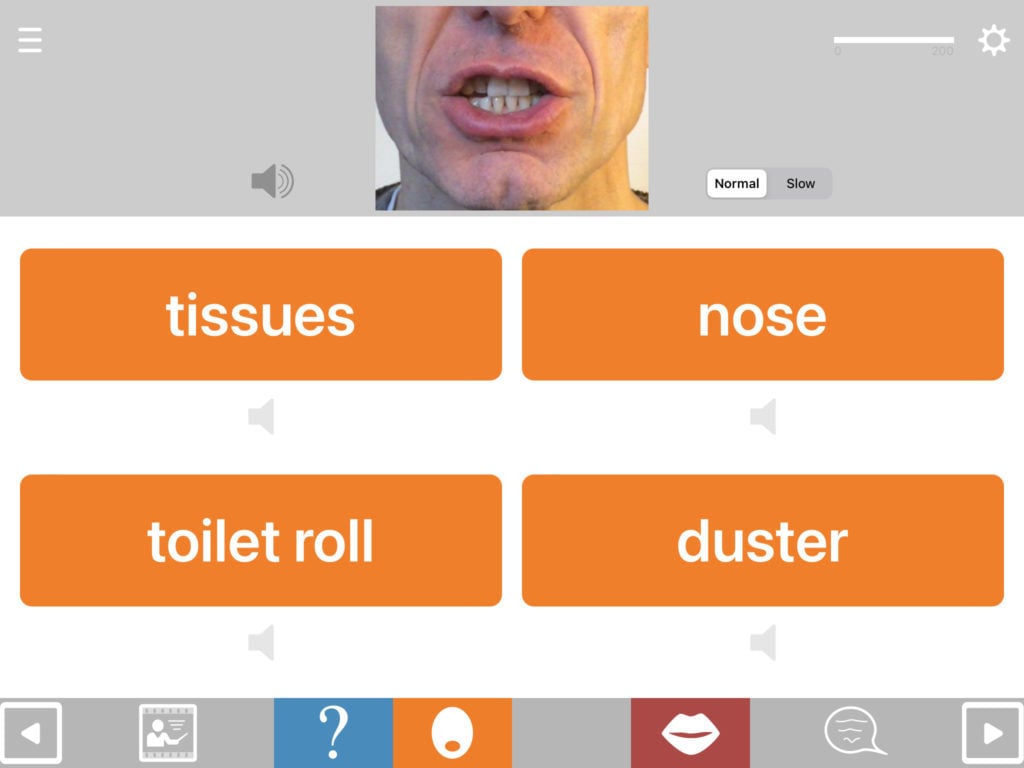
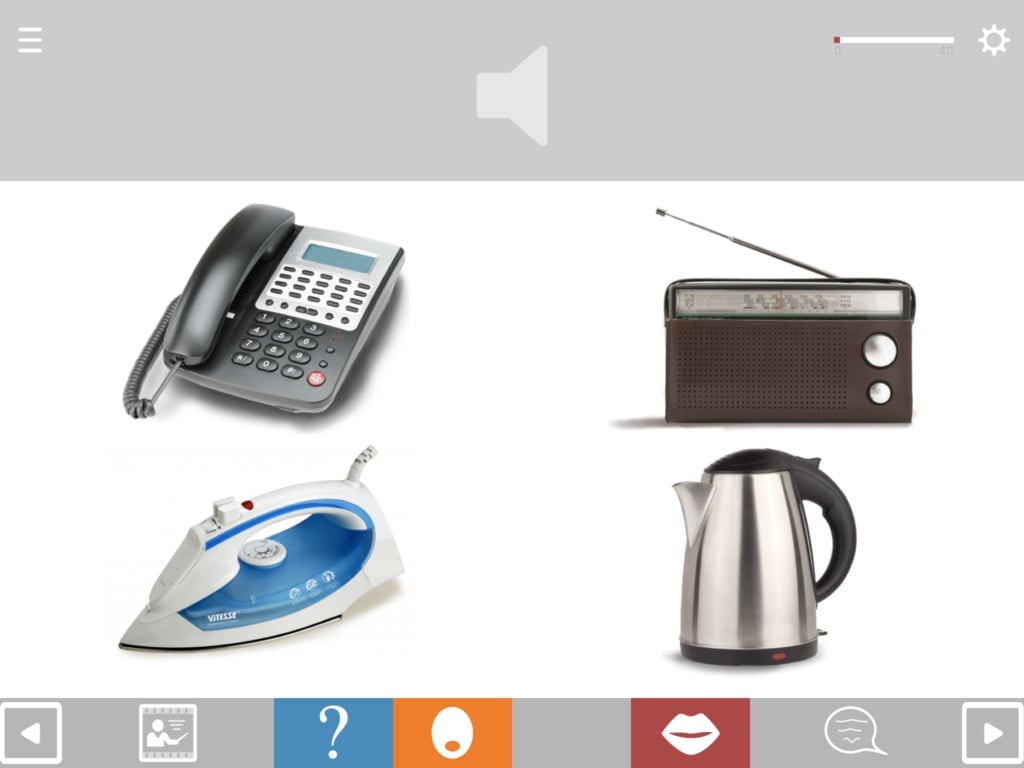
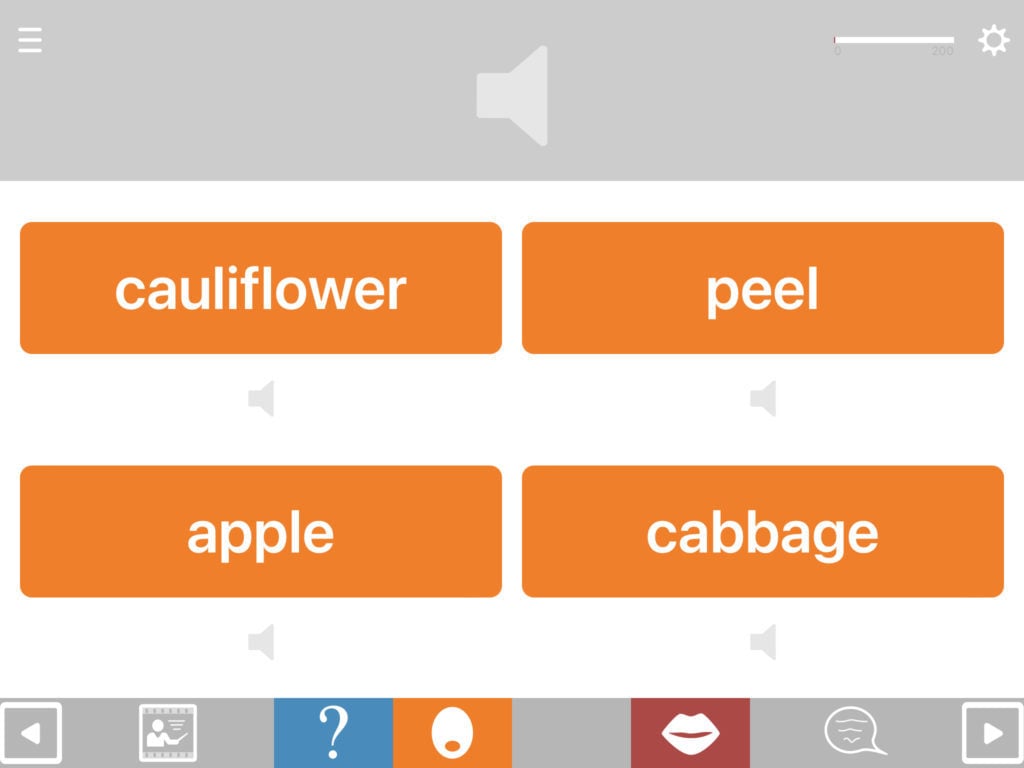
Choosing the distractors
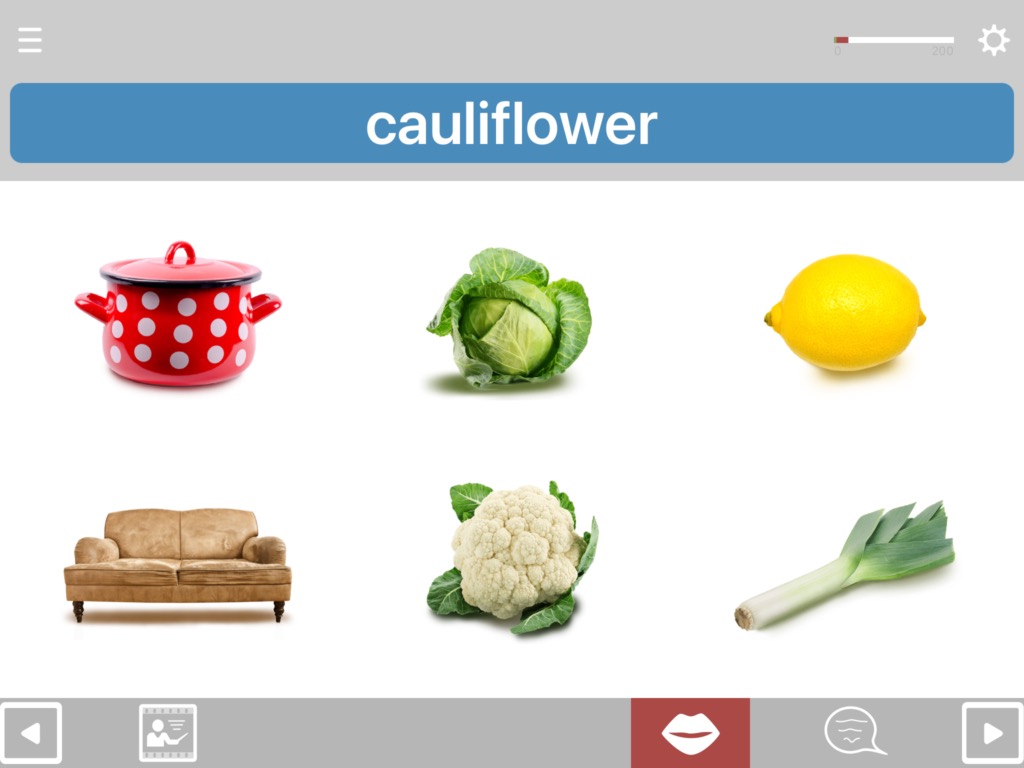
In addition to being able to choose how many distractors you want, you can also choose what types of distractors to include. For example, for nouns, in addition to the standard coordinate distractors (close or distant semantic) you can also choose to include associate distractors.
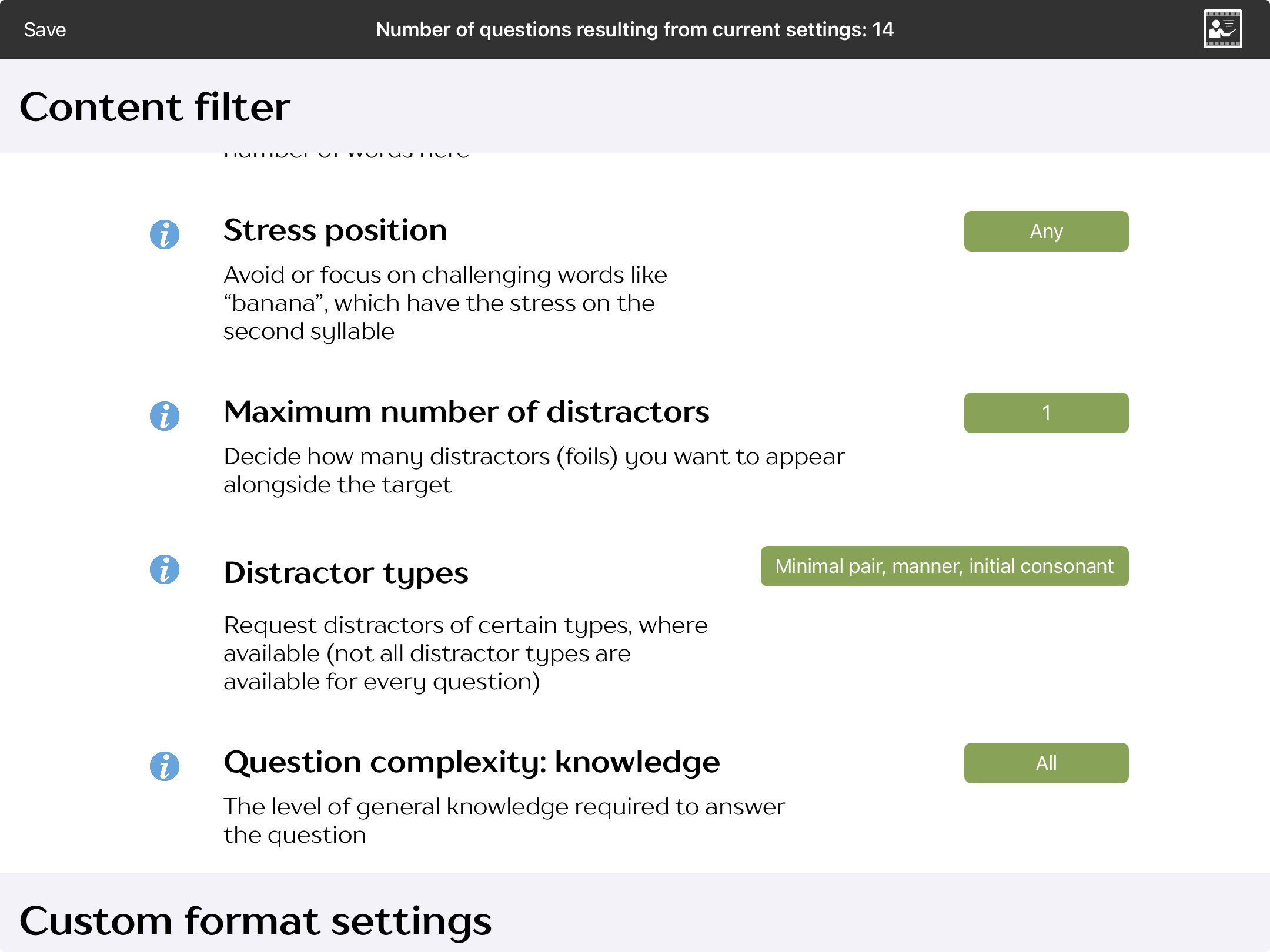
Configuring the content
In the exercise settings you can select the targets for matching according to:
- grammatical class: nouns, pronouns, verbs and a range of phrase types (found under target word/phrase type)
- word frequency: high, medium or low
- semantic category/topic: found under sets
- number of letters
- number of phonemes
- first sound
- last sound
- number of syllables
- number of words
- level of general knowledge required: allows you to remove items which require higher levels of general knowledge
Auto-advance to next item
In most of the Cuespeak modules you can modify the exercise settings so that once the main task of a question has been completed the app will move you on to the next question automatically. Whether you engage this option will depend on whether the user is likely to want to take advantage of facilities such as the articulation videos. Given that in the Matching Module the emphasis is quite heavily on the matching task rather than on word production, you might want to turn auto-advance on in this module for a smoother workflow.
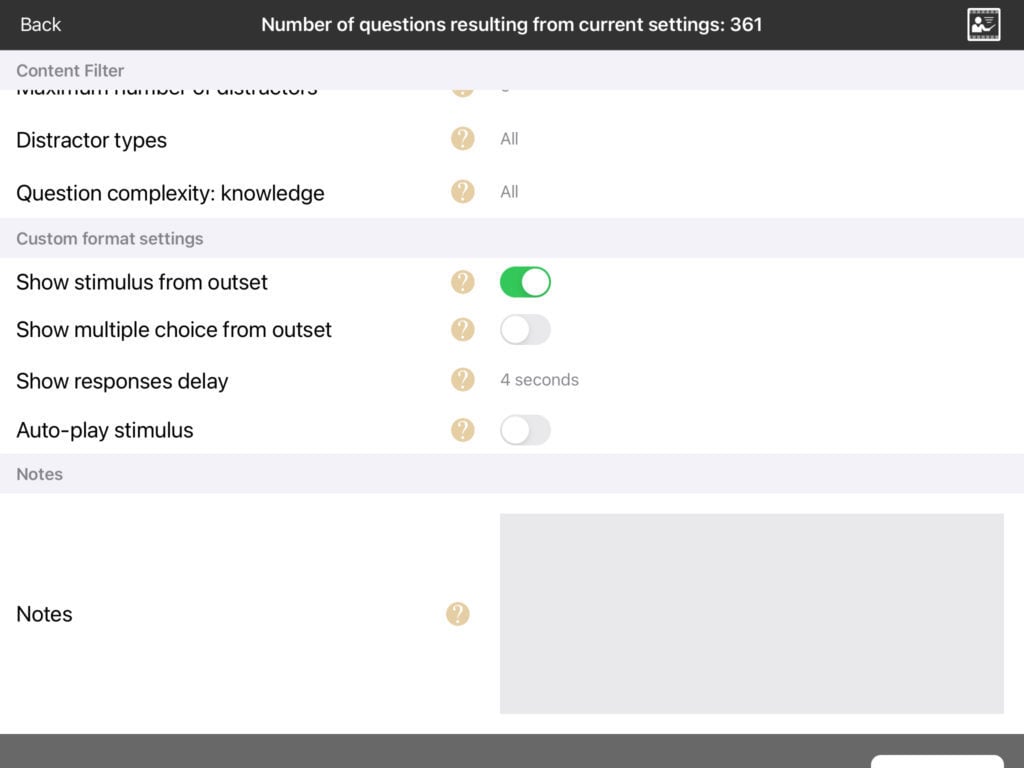
Delaying appearance of multiple choice
One problem with matching tasks is that seeing the stimulus and the multiple choice options at the same time can cause interference from one to the other, an example of top-down processing. You can eliminate this by delaying the appearance of the multiple choice option. You can specify how long you want the delay to be. To do this, switch off “show multiple choice from outset” and select the delay time in “show responses delay”.
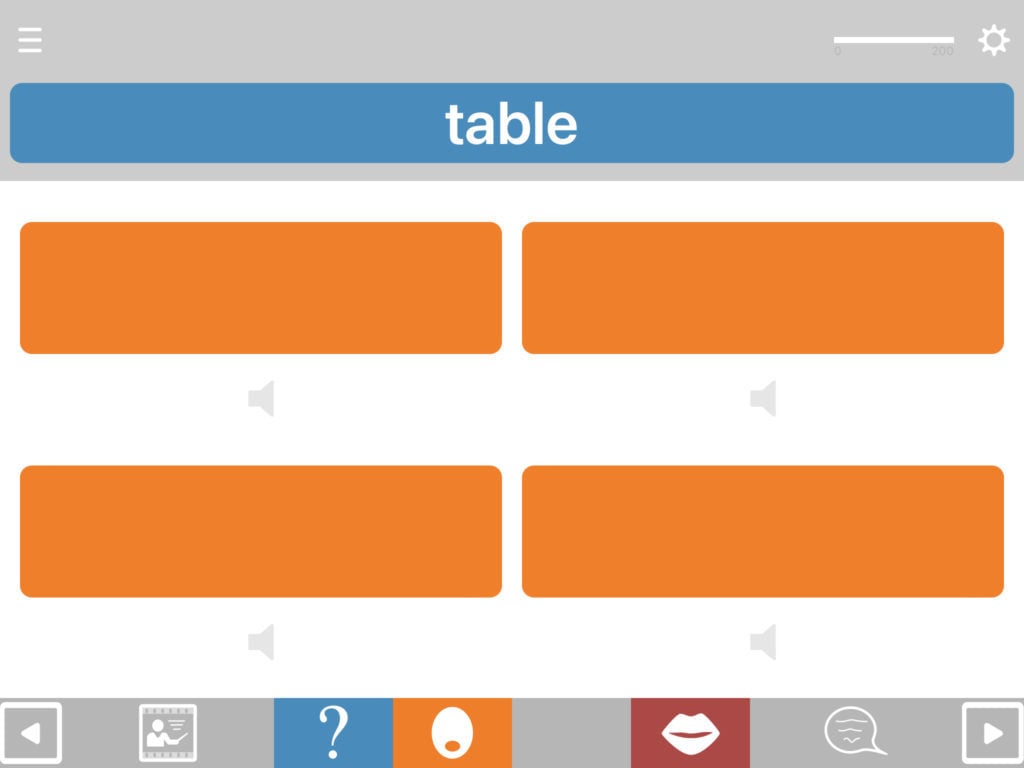
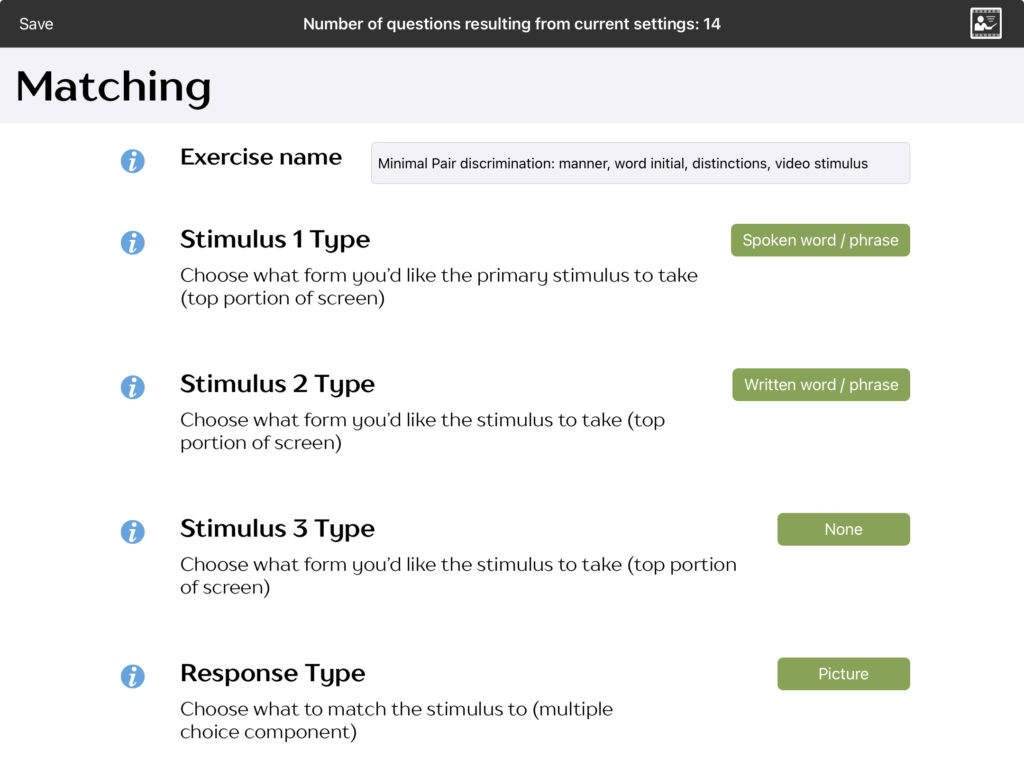
Adding customised help buttons (v.3.2 or later only)
With v.3.2 and later you can add customised help buttons in the first of up to two additional stimuli in the top half of the screen. These can be hidden initially and revealed by touching the eye symbols, or shown from the outset. Go into the exercise settings and select a “Stimulus 2 type” and “stimulus 3 type”.
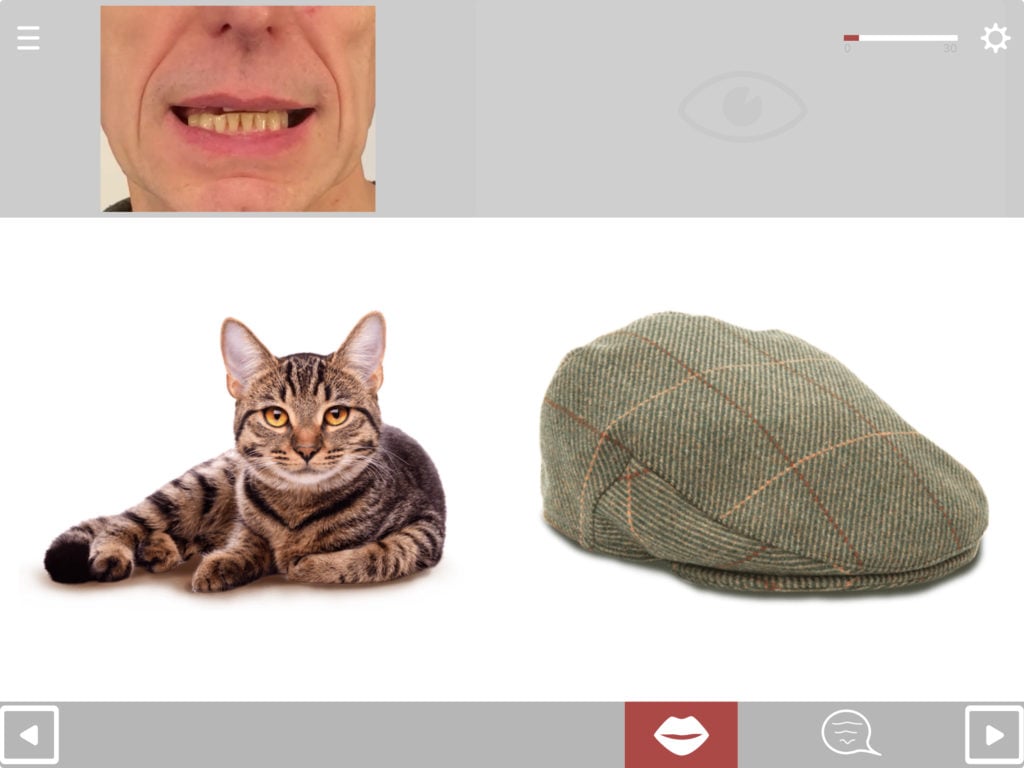
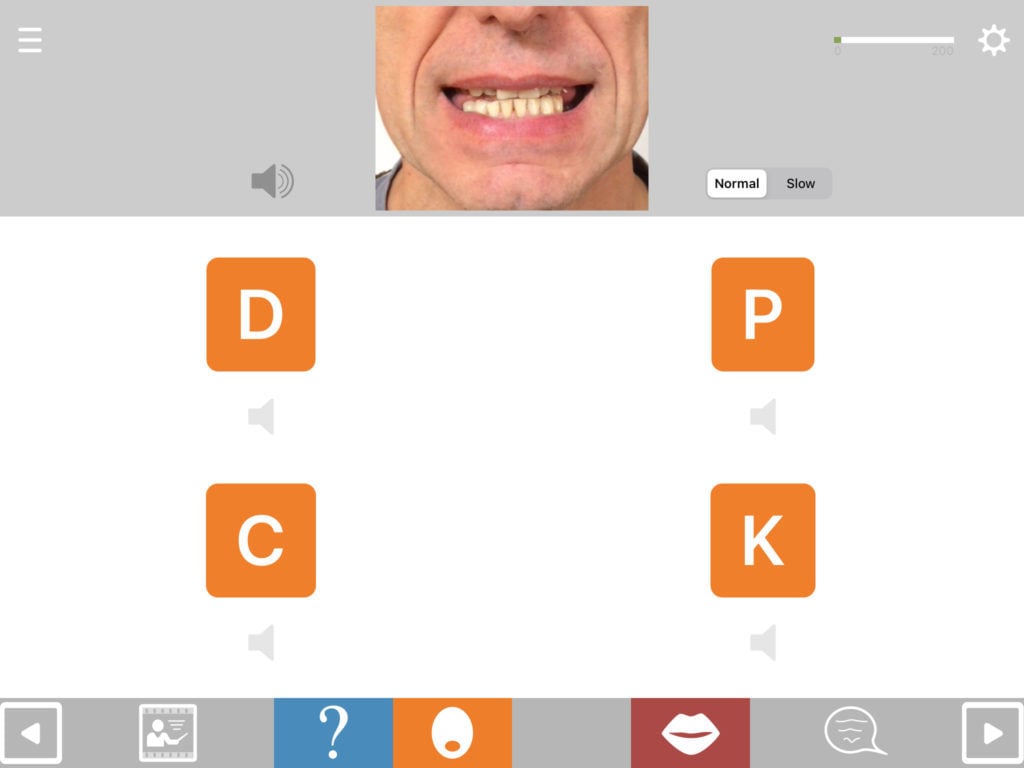
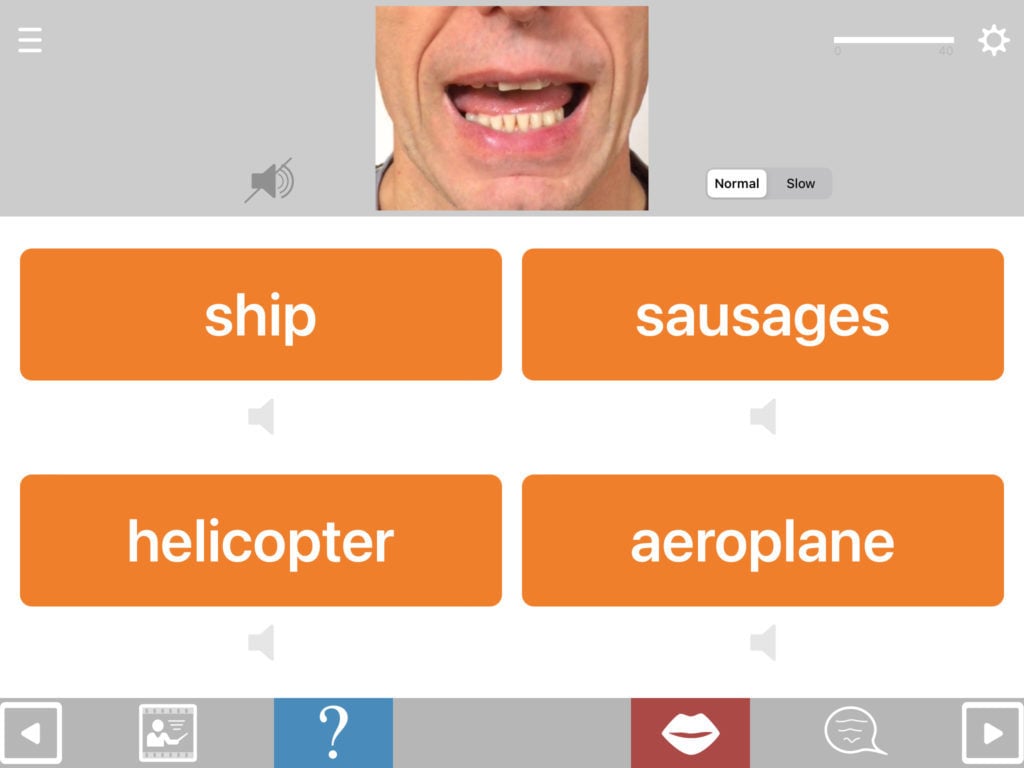
Lip-reading practice
You can also set the Matching Module to provide practice in lip-reading by selecting “silent video” as the stimulus (or if using older versions before 3.2, by turning off the sound for the standard videos within the exercise. Turning the sound off then needs to be done each time you run the exercise).
This exercise works best when the multiple choice response is set to written word/phrase.
Minimal Pairs (v.3.2 or later only)
You can create a wide range of minimal pair discrimination tasks using Matching Module. Just select “Minimal Pairs” in “Target Type” and go to “Distractor Type” to select what kind of pairs you want (voice, place, manner or a mixture). You can choose whether the stimulus be a video showing the word being spoken, or audio only.