
Purpose
Syllable Sorter presents written polysyllabic words (words with more than one syllable) with the syllables jumbled up. The user has to sort the syllables into the correct order. As you touch each syllable to place it, you hear the audio for that syllable. This means that this module can help not only with spelling but also with awareness of the sound structure of the words, as the relationship between the written and spoken forms of the word is constantly being reinforced as the task is performed. This can result in spoken word production occurring as a by-product of the spelling task.
Why two pictures?
Like the QA module, Syllable Sorter is designed to allow you to create therapy hierarchies, not just in terms of the complexity of the word or phrase to be spelt, but also in terms of the stimulus. The ultimate aim is to move beyond picture naming (see “why move beyond picture naming?”)
To this end, every spelling task in Syllable Sorter includes a question. As in QA, there is one picture to support understanding of the question and another picture to represent the answer.
Configuring the format
By hiding or showing either or both of these pictures, you can manipulate the task to create hierarchies. For example, you could begin with the equivalent of simple picture naming, showing just the target picture, then introducing the question together with the target picture, and finally removing the target picture altogether. At this point the user is required to answer a questions without the support of a picture to represent the answer. This takes us closer to the context in which word-finding occurs in a real-life setting.
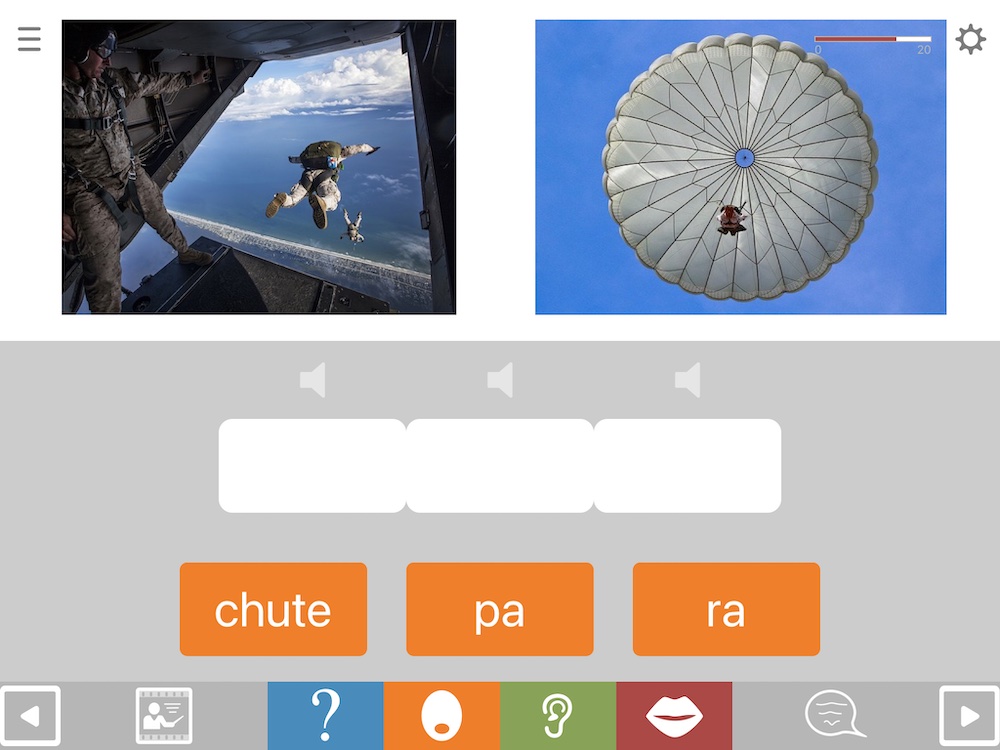
Format SyS1 shows the target picture and plays the audio. Thus it requires syllable sorting to dictation with a picture present, making it (for most people) the easiest Syllable Sorter format.
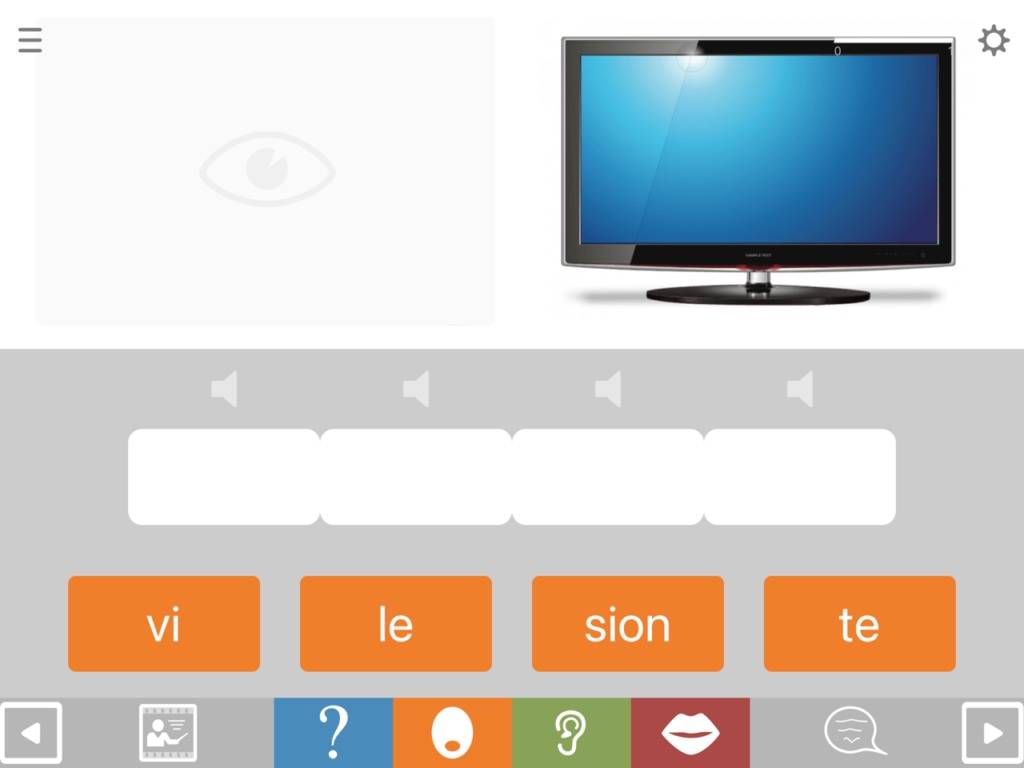
Format SyS2 also shows the target picture, but here you hear a question, in this case “What do many people watch in the evenings?”. The question serves to give extra semantic facilitation to aid the sorting task.
Format SyS3 presents the target picture with no audio to help. This is the equivalent of pure written picture naming.
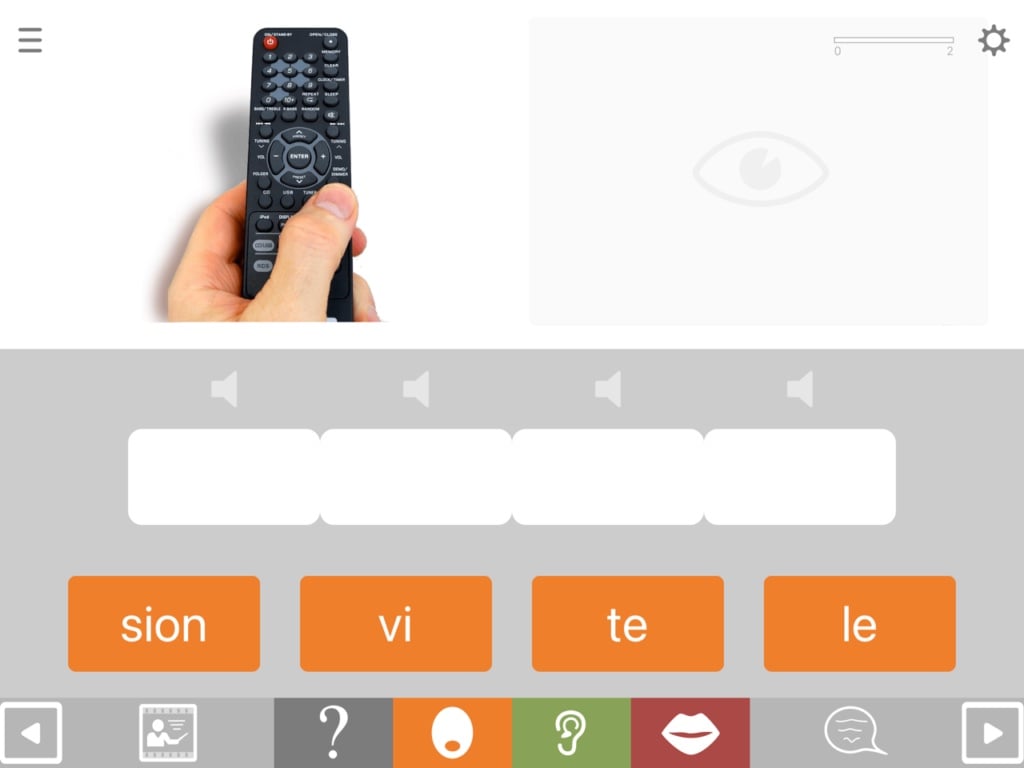
Format SS4 hides the target picture, and asks the question in audio form, e.g. “What do many people watch in the evenings?”. The picture on the left side of the screen is designed to aid understanding of the question, but it also introduces an element of contextual competition (see the article on contextual competition).
Format SS5 hides both pictures but plays the audio of the answer, making it a pure writing to dictation task.
Format SS6 also hides both pictures, but this time presents the audio question, making a task of answering a question with a written word or phrase.
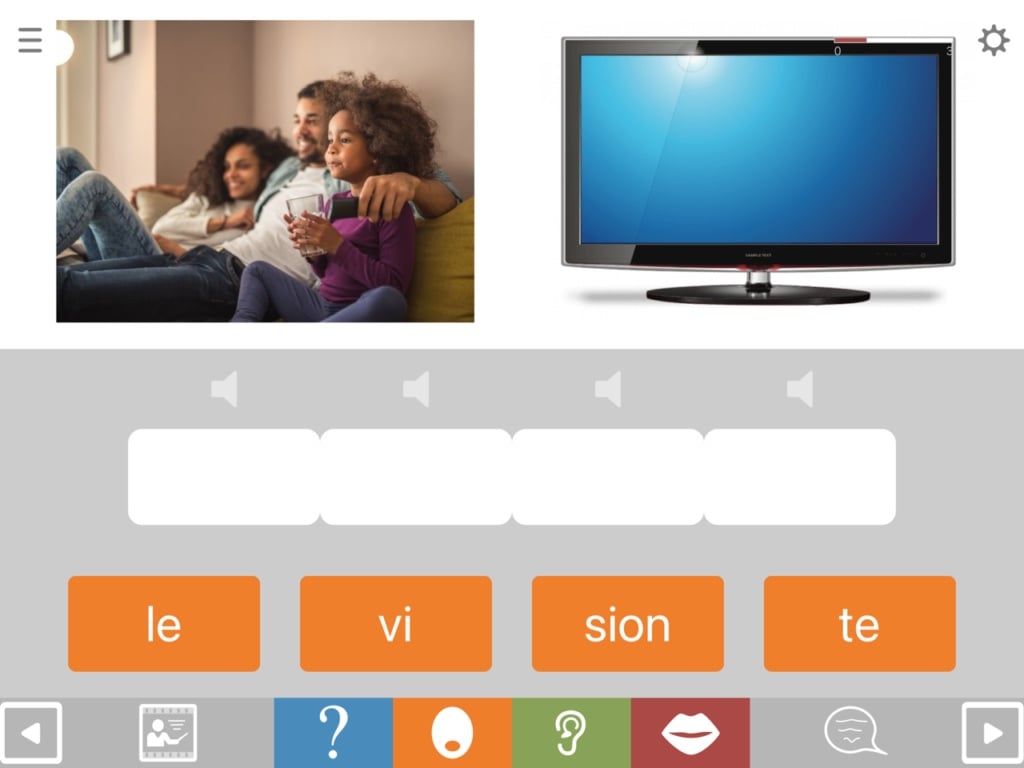
Format SS7 shows both pictures and asks the question. As in SS4 above, the picture on the left serves both to aid understanding of the question but also to introduce some contextual competition.
As with all modules in Cuespeak, the sequence of formats (1-7 here) is not intended as a prescribed hierarchy, since different people will benefit from different types of help.
Configuring the content
Configuring the content works by including in your exercise only the questions that match the criteria you specify. As you configure, you will see the number of questions (displayed on the black bar at the top of the exercise settings screen) falling with each new specification. However, because this module contains around 500 questions, it can be configured quite heavily and still retain substantial amounts of content.
In just a few seconds you can configure Soundspell to work on spelling anything from common everyday words through to complex, high level vocabulary, using the following settings:
Target type: This refers to the grammatical class of the target words. Most targets in this module are nouns, but there is also a reasonable number of verbs. For most users it’s fine to leave this field unconfigured, since most people will want to work on all grammatical classes.
Word frequency: Allows you to select more common (“high frequency”) words and phrases or less common “low frequency” ones.
Sets: Allows you to select the topic area the questions will cover, such as news & current affairs, health or travel. You can also use it to select sets of 20 common words to work on intensively – the same sets as in the QA module.
Number of letters: For most users this can be left unconfigured, since the next field (number of phonemes) is far more significant in this module in terms of word length.
Number of phonemes: In this spelling task, each tile represents a single phoneme (speech sound). For this reason, number of phonemes is a more significant variable here than number of letters (above), which would be a major variable in other spelling tasks. You can limit target words to those containing as little as two phonemes, such as “shoe” or “key”. NB you need to select all the numbers you want, e.g if you want words of up to 3 phonemes you need to select 1 2 and 3.
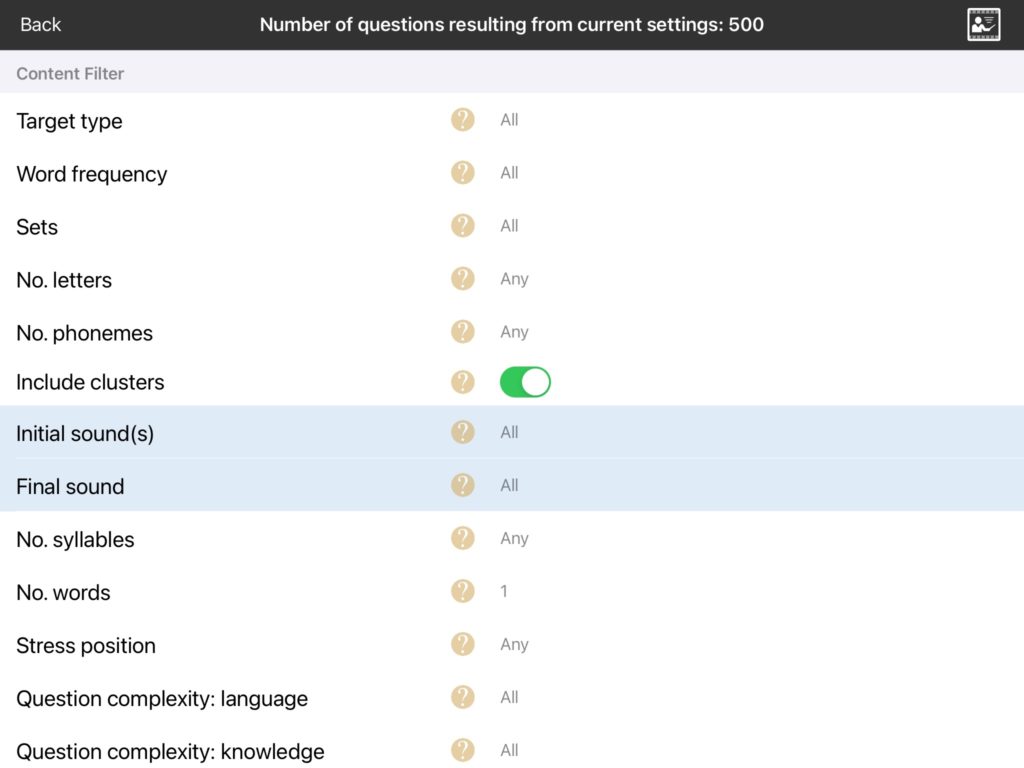
Include clusters: Allows you to remove words beginning with consonant clusters such as bread or snow. This will only be an issue for people focussing on saying the target words as well as spelling them.
Initial & final sounds: This allows you to include only target words beginning with a specified sound (phoneme). You might want to do this if you want to focus work on particular sounds or temporarily avoid problematic ones. You can control both word initial sounds and word final sounds in this way. Be aware that this applies to sounds, not to letters. So for example if you select the sound /s/ you will get words such as “cereal” or “ceiling” as well as those beginning with the letter S.
Number of syllables: This allows you to specify the number of syllables the target words should have. You need to select all the numbers you want, e.g. If you want to work on words of 1, 2 and 3 syllables, you need to select all three of those numbers. If you want to work specifically on syllable structure, you might prefer to use the Syllable Sorter module.
Number of words: By default Syllable Sorter delivers only single words, since these make the most intuitive sense in this module. However you can reset it to include phrases.
Stress position: Some people with aphasia have particular difficulty with words in which the stressed syllable is not the first syllable, e.g. “banana”. This will only be an issue for people wanting to say the words as well as spelling them.
Question complexity: language: Unlike most controls in this section, the question complexity filters allow you to adjust the complexity of the question rather than of the answer. This one controls the complexity of the language used in the question, both in terms of syntax and word frequency. It is a subjective measure only. NB You need to select all the levels you want, e.g. if you select “moderate” this will exclude “easy” questions unless you also select “easy”.
Question complexity: knowledge required: This allows you to control the level of general knowledge required by the question. Easier questions cover very familiar, everyday material, while harder questions cover more specialist knowledge such as you might find in a quiz. In some cases questions have been rated as “difficult” on the basis of the cognitive reasoning they require as much as actual knowledge. NB You need to select all the levels you want, e.g. if you select “moderate” this will exclude “easy” questions unless you also select “easy”.
Custom format settings: This section contains two useful options:
- Show tile content from outset: Turning this off make the spelling tiles blank. This is useful for working on sound sequencing. For more details see sound sequencing: spelling with blank tiles.
- Requires correct phoneme & grapheme: Some words contain multiple instances of the same syllable representing different sounds. For example, in the word “BANANA” the first NA syllable sounds different from the second NA. By default, Cuespeak will not insist on these letters being placed in their precise corresponding positions. The result is that the duplicate letter sequences may sound out incorrectly when touched. If you want to change this to insist on correct placement of duplicate tiles, turn on “requires correct phoneme and grapheme“.