
What is QA for?
With over 2000 questions to draw from, QA (short for Questions and Answers) allows you to create exercises for any severity of aphasia to work on:
- Word-finding
- Spoken word production
- Understanding spoken questions (auditory comprehension)
- Understanding written questions (reading comprehension)
- Connections between concepts (semantic associations)
QA is also useful as an assessment tool, as it provides a quick overview of a number of important aspects of aphasia – see the section below on assessment.
In essence, QA poses a spoken or written question (top half of screen) and then offers a range of types of help to answer that question (lower half of screen).
By configuring the content and the format you can adjust the level of difficulty and shift the emphasis of the exercise onto any of the above areas.
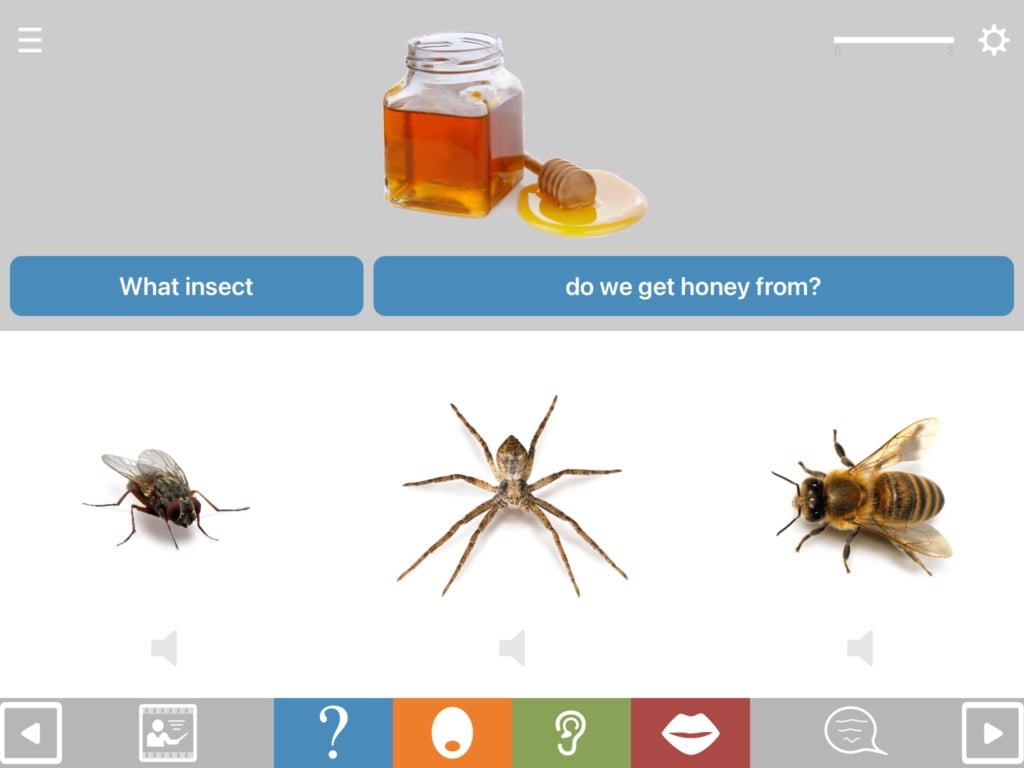
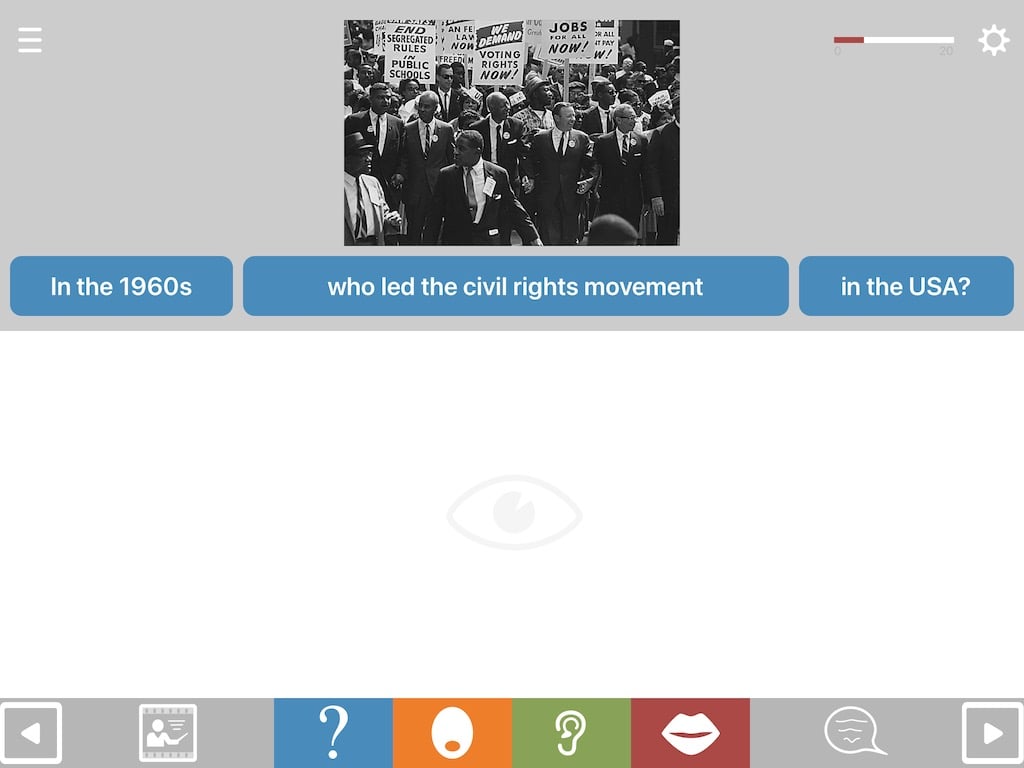
Help for understanding the question
Above the question is a picture designed to boost understanding of the question. If the user nevertheless has difficulty understanding the spoken question, they can hear it again in chunks by tapping the blue written question TABs (text-audio boxes) at their own pace.
You can also control the speed at which the question is delivered, by going into the main app settings and selecting speech controls.
You can also select easier questions by adjusting question complexity in the exercise settings. This allows you to control both the linguistic complexity and the level of general knowledge required.
Help for answering the question
If the user is unable to answer the questions, there is a choice of types of help available.
First, you can provide a multiple choice picture response (formats QA1 and QA3). If the user selects the wrong picture, they will get spoken feedback on the error. If they select the correct picture, they will get whatever spoken feedback you programme the module to deliver. The choice (found in exercise settings under feedback on correct selection) is:
- The spoken answer to the question, often within a phrase, e.g. “in the kitchen”.
- The spoken name of the pictured item, isolated (e.g “kitchen”)
- A closure cue designed to elicit the answer (e.g. “You cook meals in the……”).
- Closure cue followed by the spoken answer after a short delay. This is the default setting for most formats.
- No feedback
Which of these types of feedback you choose will depend on what the user wants to focus on, and on how much benefit they derive from each. For example, some users benefit greatly from the closure cues, while others don’t.
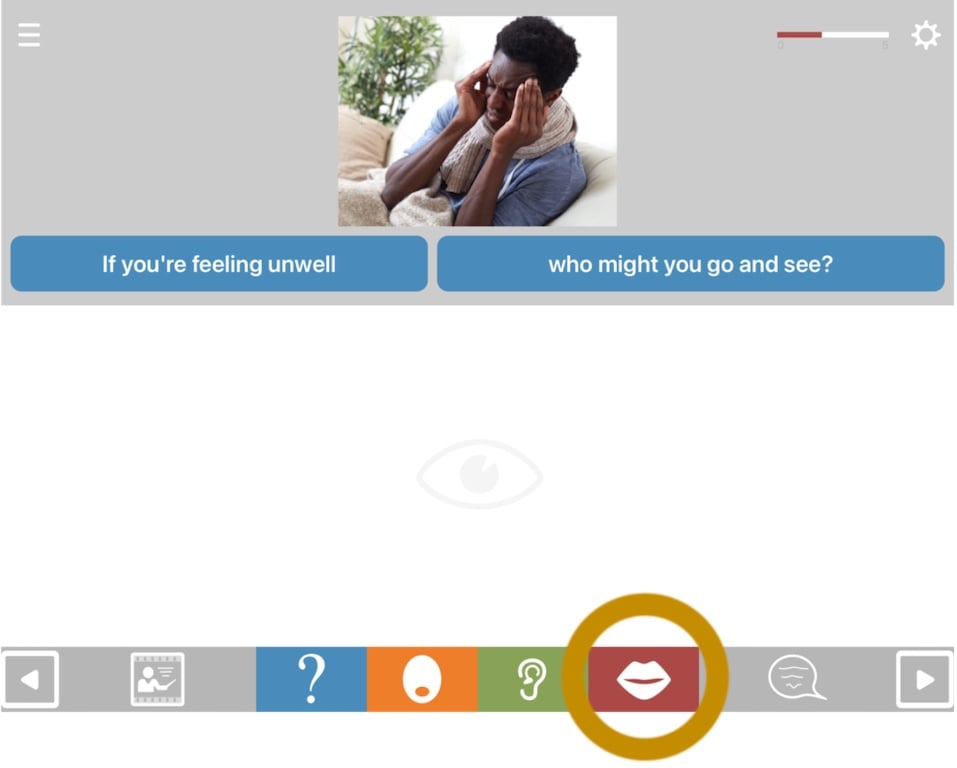
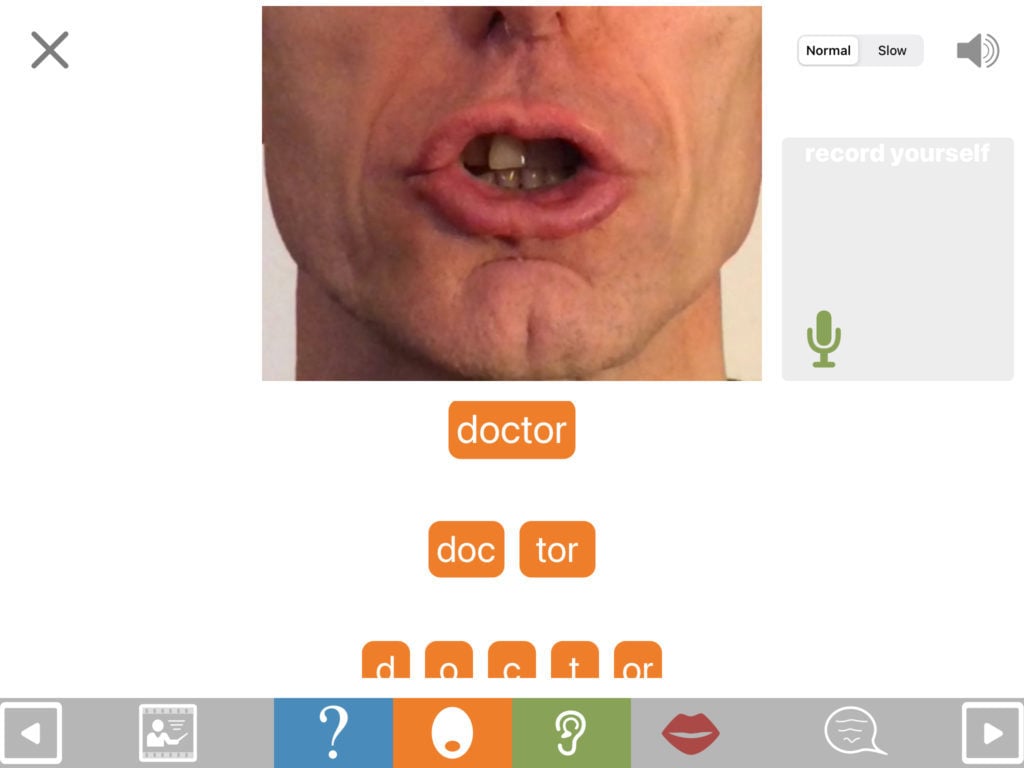
If the closure cue is not effective, the user might benefit from viewing the articulation videos. To view these, tap the red button on the bottom toolbar. The main video shows the answer spoken as a whole word or phrase. Separate videos show the component words, syllables or sounds, depending on the nature of the answer. You may need to scroll down to view these.
Configuring the format
You can radically change the demands of the QA module by selecting from 13 different formats which show or play different elements. To find these, go into exercise settings and tap format. This enables you not ony to change the focus of the task, but also to create carefully graded hierarchies, gradually making the task more demanding over time.
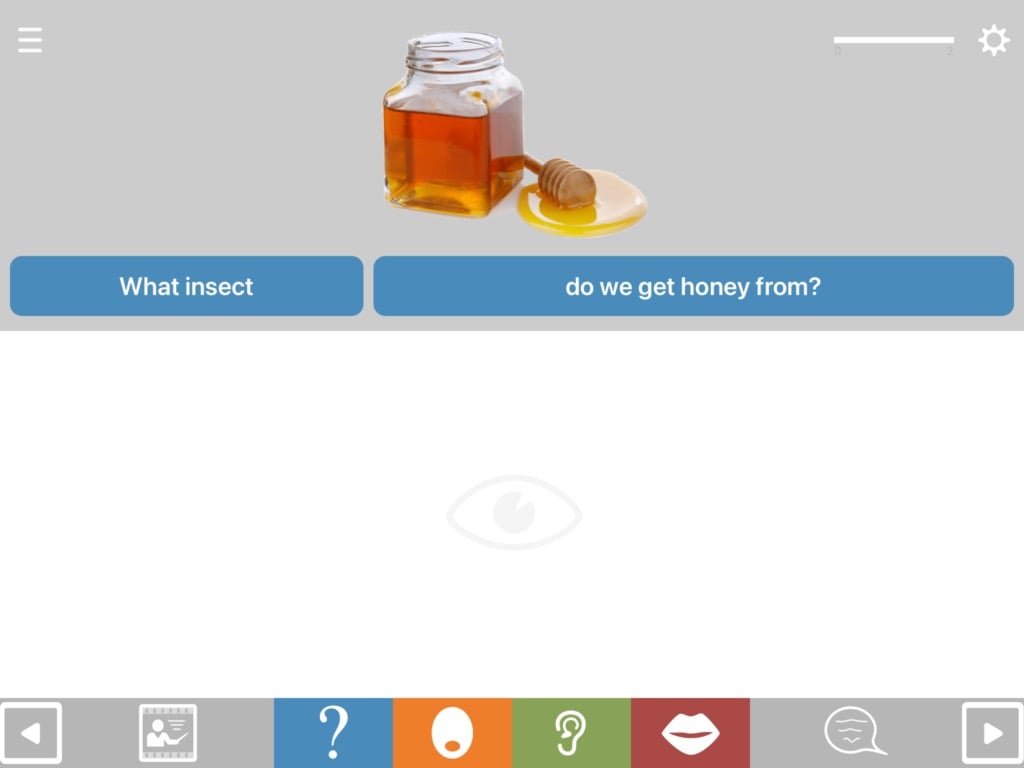
Format QA1 displays all the pictures and delivers the question in both spoken and written form. QA1a presents the question in spoken form only (“a” stands for “auditory”), while QA1w presents it just in written form, allowing you to work on reading comprehension.
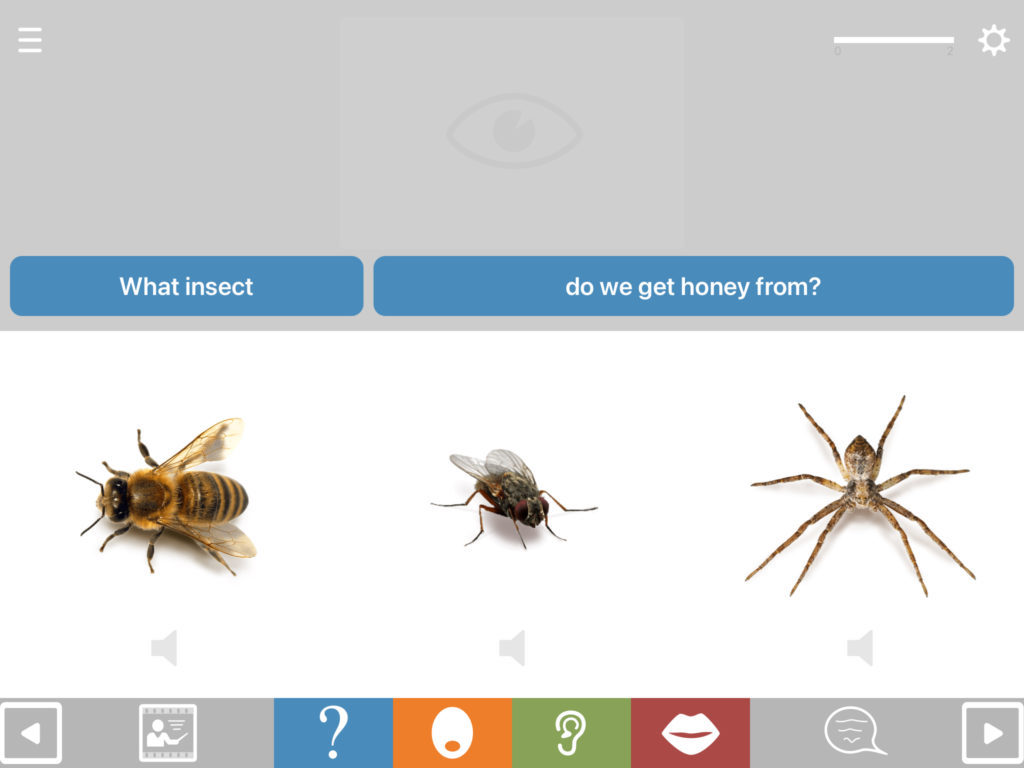
Format QA2 hides the multiple choice pictures, placing heavier demands on the cognitive system, as there is no longer a picture to represent the answer. In order to answer the question, the user now has to generate an internal representation of the concept. Thus we move away from mere naming of pictures into something closer to the demands of real life communication, since we seldom “name” things in conversation, but instead refer to abstract concepts and things that are not present.
When the multiple choice pictures are hidden, the bottom toolbar will remain in place, so the orange button, for example, will still allow you to listen to the closure cues.
Although the multiple choice pictures are now hidden, the option remains to reveal them if the user is struggling. Just touch the feint eye symbol in the lower half of the screen and the multiple choice pictures will appear. This applies to any hidden element on the exercise screen, in any module.
Format QA3 hides the top picture. Since the purpose of the top picture is to aid understanding of the question, hiding it places more demand on the user’s understanding, whether it’s in spoken form as in QA3a (the a stands for “auditory”), written form (QA3w, the w stands for “written”) or both (QA3).
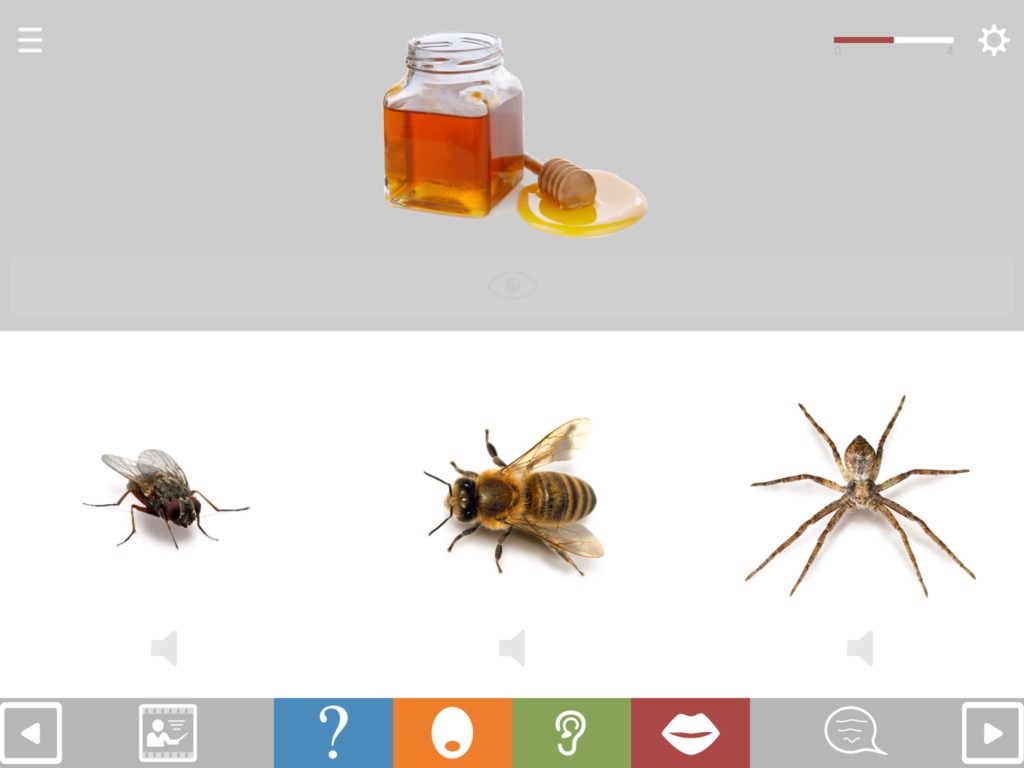
Format QA4 hides all the pictures, placing heavier demands on both understanding and word retrieval. Again the question can be presented in spoken form (QA4a) or written (QA4w).

Format QA5 presents all the pictures but removes the question. It requires the user simply to decide which of the multiple choice pictures has something to do with the top picture.
You might expect associating pictures to be easier than answering questions, but this is not always the case. This is because the question, when present, serves to point out the nature of the association between the top picture and the target picture. The absence of the question means that the user has to identify the association without help. This module can be useful for identifying fragility in the semantic network, in the same way the Pyramids & Palm Trees assessment tool does.
Configuring the content
Content-wise you can modify the complexity of the question, the complexity of the answer and a huge range of other linguistic variables, allowing you to target language very systematically according to the needs of the individual.
Configuring the content works by including in your exercise only the questions that match the criteria you specify. As you configure, you will see the number of questions (displayed on the black bar at the top of the exercise settings screen) falling with each new specification. However, because the module contains over 2000 questions, it can be configured quite heavily and still retain substantial amounts of content.

In just a few seconds you can configure QA to work on anything from common everyday words through to complex, high level vocabulary, using the following settings:
Target type: This refers to the grammatical class of the target words. Most targets in this module are nouns, but there is also a reasonable number of verbs. For most users it’s fine to leave this field unconfigured, since most people will want to work on all grammatical classes.
Word frequency: Allows you to select more common (“high frequency”) words and phrases or less common “low frequency” ones.
Sets: Allows you to select the topic area the questions will cover, such as news & current affairs, health or travel. You can also use it to select sets of 20 common words to work on intensively.
Number of letters: For most users this can be left unconfigured, since the next field (number of phonemes) is far more significant in this module in terms of word length.
Number of phonemes: If the user has difficulty producing speech sounds and sequencing them to form words, one of the the most important parameters to configure in exercise sttings is likely to be number of phonemes. You can limit target words to those containing as little as two “phonemes” (speech sounds), such as “shoe” or “key”. NB you need to select all the numbers you want, e.g if you want words of up to 3 phonemes you need to select 1 2 and 3.
Include clusters: Allows you to remove words beginning with consonant clusters such as bread or snow. Such words can pose extra challenges to some users, so you might sometimes want to exclude them if their inclusion causes undue frustration. If you want to exclude specific clusters only, you can do this in the next field, “initial and final sounds”.
Initial & final sounds: This allows you to include only target words beginning with a specified sound (phoneme). You might want to do this if you want to focus work on particular sounds or temporarily avoid very problematic ones. You can control both word initial sounds and word final sounds in this way.
Number of syllables: This allows you to specify the number of syllables the target words should have. You might want to restrict the selection to single syllable words, or you might want to focus particularly on polysyllabic words. You need to select all the numbers you want, e.g. If you want to work on words of 1, 2 and 3 syllables, you need to select all three of those numbers.
Number of words: This allows you to remove multi-word phrases from the target selection. You might want to do this, for example, if you’re working on polysyllabic words, as you will probably then want to exclude targets in which the syllables are separate words.
Stress position: Some people with aphasia have particular difficulty with words in which the stressed syllable is not the first syllable, e.g. “banana”. This allows you to exclude them, or to focus on them solely.
Question complexity: language: Unlike most controls in this section, the question complexity filters allow you to adjust the complexity of the question rather than of the answer. This one controls the complexity of the language used in the question, both in terms of syntax and word frequency. It is a subjective measure only. Bear in mind that in many variants of QA (e.g. QA5) the question is in fact redundant, i.e. the multiple choice element can be completed solely on the basis of the pictures. NB You need to select all the levels you want, e.g. if you select “moderate” this will exclude “easy” questions unless you also select “easy”.
Question complexity: knowledge required: This allows you to control the level of general knowledge required by the question. Easier questions cover very familiar, everyday material, while harder questions cover more specialist knowledge such as you might find in a quiz. In some cases questions have been rated as “difficult” on the basis of the cognitive reasoning they require as much as actual knowledge. NB You need to select all the levels you want, e.g. if you select “moderate” this will exclude “easy” questions unless you also select “easy”.
Custom format settings: You won’t normally need to use these – they allow you to create bespoke formats other than those available in the format presets above.

Using QA for assessment
QA can provide useful insights into the nature of someone’s aphasia, and into what helps.
You’ll want to base your intial settings on the impression you’ve gained from observing the person’s spontaneous communication. If, for example, the person has no substantial spontaneous speech, you might be interested in:
(a) can they produce any substantial speech with support?
(b) if they can’t, can they nevertheless complete the multiple choice component successfully? The ability to do so would suggest that they have understood the question and know the answer at the conceptual level.
It’s often best to start with the QA1 format, which includes the mutliple choice element from the outset. However if you’re concerned that seeing everything at once will be overwhelming, set it to QA2, which hides the multiple choice element initially. Once it seems the person has processed the question, you can then reveal the multiple choice pictures (by tapping the eye symbol).
As for what content to include for assessment, this will again depend on your impressions of the person’s spontaneous communication. If the person has little or no spontaneous spoken output, you might want to start with questions in which the target answer is a common word with just two or three sounds in it, such as “key” or “bed”. It’s also worth leaving in place the default condition whereby tapping the correct picture triggers a closure cue, since it can be useful to find out whether this helps the person to say the answer to the question.
It’s usually best to err on the side of making the task too easy initially rather than too difficult, since too much struggle can be discouraging. If it’s too easy you can adjust it to make it more demanding in just a few seconds by going back into the exercise settings.
If someone has difficulty answering a question, it’s not always obvious what factors are contributing to this difficulty. Was it:
- difficulty understanding the question?
- difficulty forming the answer at the conceptual level?
- difficulty finding the words?
- difficulty articulating the words?
- a combination of these?
Experiment to shed some light on what factors are at play:
- repeat or re-phrase the question
- show the target picture (you can pinch out on it to zoom it to full screen size)
- try the closure cue
- show the articultation video
For further thoughts about what can underlie apparent word-finding difficulties, see the section on competition in word-finding.